- Published on
GPT - From Language Modeling to General Intelligence
- Authors

- Name
- Trong Nguyen
The previous post explored an overview of Transformer about how tokens are embedded, how attention lets every position look at every other, and how stacking encoder and decoder layers produces rich and context-aware representations. The conclusion mentioned briefly about GPT as an example of a decoder-only model. I decided to choose GPT as the topic of this post because ChatGPT was the first LLM that I tried and is currently still one of the most popular LLMs.
TL;DR
- GPT strips the Transformer down to decoder-only: no encoder, no cross-attention, just causal self-attention and feed-forward layers
- The training objective is simple: predict the next token. Any raw text is valid training data without annotation
- GPT-1 explored the pre-train then fine-tune paradigm on decoder-only architecture: learn representations from unlabeled text, then adapt with task-specific labeled data
- GPT-2 scaled data diversity (WebText) and showed zero-shot generalization is possible without fine-tuning
- GPT-3 pushed to 175 billion parameters, where in-context learning emerged as a qualitatively new capability
- GPT-3.5 and ChatGPT applied RLHF to encode human preferences directly into model behavior, showing alignment and raw scale are separate axes
- GPT-4 expanded to multimodal input and treated safety as a training-time design concern rather than an afterthought
- GPT-5 unified the standard and reasoning model lines with a learned routing system
1. Generative Pre-trained Transformer
GPT stands for Generative Pre-trained Transformer, a family of models developed by OpenAI starting in 2018. The core idea is surprisingly simple: take the decoder part of the Transformer, train it to predict the next token in a sequence, and apply it at scale. What were achieved from this process turns out to be far more capable than anyone expected.
1.1 From Transformer to GPT
The original Transformer was designed for sequence-to-sequence tasks, specifically for machine translation. Its architecture can be interpreted for that purpose: the encoder compresses the input sequence into contextual embeddings, then the decoder generates the output sequence token by token based on those embeddings (and previous outputted tokens). The two halves are coupled through cross-attention, which is a sub-layer in each decoder block, to allow the decoder look back at the encoder's output. This architecture is particularly well suited to tasks where an input sequence must be transformed into a related output sequence, such as machine translation.
OpenAI addressed that constraint by simplifying the considered problem into a more fundamental task: text generation. In that case, the difference between the source and target is much smaller (e.g. single token) while they are still semantic aligned. The compression of encoder is thus unnecessary, and using only decoder to generate next tokens is sufficient enough. With the removal of encoder part, the computation within a decoder layer is also reduced since its cross-attention block (which connects to the encoder's output) is discarded. Finally, what remained was a stack of layers, each containing only two sub-components: a masked self-attention block (which enforces the autoregressive property) and a feed-forward network, each wrapped in residual connection and layer normalization.
The training objective follows directly from this setup. Given a sequence of tokens, the model is trained to maximize the likelihood of each token given all preceding tokens:
This problem formulation implicitly provides the supervision (a token is the expected output given the sequence of all previous tokens) while there is no human annotation required.
1.2 The Decoder-Only Architecture
The input preparation pipeline follows the same structure described in the previous post. Text is tokenized, each token is mapped to an embedding vector via a lookup table, learned positional encodings are added, and the result is passed through the stack of layers. At the output end, the final layer's hidden state for each position is projected through a linear layer into a vector of vocabulary size, and softmax produces a probability distribution over the next token.
GPT ties the input embedding matrix and output projection matrix, reducing parameters and often improving language modeling performance. In other words, the weights of the embedding matrix are shared for both ends of the model flow. Concretely, the same matrix that maps token IDs to embedding vectors is reused (transposed) to project hidden states back into vocabulary space. The model then can learn representations that are useful both for “encoding” a token as input and for “recognizing” it as output. In training phase, the embedding layer's weights are updated from two corresponding gradient sources.
The following table is a brief architecture comparison between Transformer and GPT, in which the latter is much more straightforward compared to the former.
| Transformer | GPT | |
|---|---|---|
| Architecture | Encoder + Decoder | Decoder only |
| Self-attention | Bidirectional* (encoder), Causal (decoder) | Causal only |
| Cross-attention | Yes | No |
| Training objective | Next token (decoder) + teacher forcing | Next token (autoregressive) |
| Primary use | Sequence-to-sequence | Text generation |
* Bidirectional is used in terms of the directions that a token looks at, should not be confused with BERT (where the well-known term “bidirectional” is associated with).
What makes this simplification more powerful than the original architecture comes from the nature fit of the optimization objective and the available data. Any raw text can simply be converted to token sequences via tokenizer, and that's all what needed for dealing with token prediction (no annotated datasets or task-specific structure required). The entirety of written language becomes a valid training data. This is the foundation on which all subsequent GPT models are built.
2. GPT-1: Semi-supervised training
The first GPT model, introduced in Improving Language Understanding by Generative Pre-Training, was built as a 2-stage optimization: using a large corpus of unlabeled text to learn effective hidden token representations, then adapting it for discriminate tasks with labeled data.
2.1 Pre-training on Language Modeling
GPT-1 was trained on BookCorpus, a dataset of approximately 7,000 unpublished books of various genres. The reasoning behind this choice was that books contain long stretches of coherent, flowing text with complex inter-sentence dependencies, which forces the model to learn more than just local word co-occurrences. With a context window of 512 tokens, the model was expected to capture both local syntax and longer-range semantic structure.
The computation of the model can be summarized as
where is the token vectors within the context of size (512 in the experiment of this paper), is the number of decoder layers , and are respectively the token and positional embedding matrices. It is obvious that the token embedding is shared for both input and softmax () layers.
Architecturally, GPT-1 is a 12-layer decoder-only Transformer with a hidden size of 768 and 12 attention heads. The feed-forward inner dimension is 3072, following the same expansion ratio used in the original Transformer. In total, the model has around 117 million parameters.
| Hyperparameter | Value |
|---|---|
| Layers | 12 |
| Hidden size | 768 |
| Attention heads | 12 |
| FFN inner dimension | 3072 |
| Context window | 512 tokens |
| Parameters | ~117M |
| Training data | BookCorpus (~5GB) |
2.2 Fine-tuning on Downstream Tasks
The model pre-trained in the previous step is not ready for a specific task yet. There is then a second stage of using a labeled dataset (which is relevant to the target task) to fine-tune the model's weights. A linear layer is placed on top of the final hidden state of the last token for predicting a label. Different from typical training strategy, the whole model is optimized jointly in this stage, i.e. the pre-trained weights are not frozen. The previous stage thus can be considered as an advanced weight initialization. The objective of the linear layer is to estimate a probability (via softmax) for each label given an input
where is a sequence of tokens and is a label, is the activation of the last decoder after passing the last token , and is the weights of the task-specified linear layer.
A challenge in fine-tuning was handling the variety of task formats: some take a single sentence as input (sentiment analysis), while others require a pair of sentences (entailment, similarity) or multiple candidates (multiple choice). Instead of designing separate input pipelines for each format, a scheme of task-specific input transformation was introduced.
As the pre-training was performed with flat token sequence, the idea is to define a delimiter $ concatenating elements in the input (depending on the task) to always represent the model's input under the same format:
- Textual entailment: the premise is concatenated with hypothesis to form $ sequence
- Similarity: two inputs of possible orderings $ and $ are both considered (as order does not matter in similarity) by being fed into decoders, then added element-wise before reaching the linear layer at the end
- Question answering, commonsense reasoning: given context document , question , and set of possible answers , the input is formed for each answer as $ , they are then processed independently and finally normalized via a softmax layer to output a distribution over possible answers.
An illustration of the input transformation scheme is given in the paper as follows. Note that the model's input is always warped by a pair of tokens <s> (start) and <e> (end, or “extract” 🫨 in the figure).
)](/_next/image/?url=%2Fstatic%2Fimages%2Fposts%2Fgpt%2Fgpt-1-architecture.png&w=3840&q=70)
GPT architecture & its strategy to adapt model flow for fine-tuning (from the original paper)
This is an elegant solution because it means the model architecture itself does not change at all between tasks. Only the input format and the final linear layer need to be adapted while the pre-trained representations transfer directly.
2.3 What GPT-1 Proved
GPT-1 demonstrated that the two-stage paradigm (pre-train on language, then fine-tune on tasks) is an effective strategy. It outperformed task-specific models on 9 out of 12 benchmarks, despite those competitors being trained exclusively on labeled data for each individual task. In summary, pre-training can let model learn something real about language that transfers across domains.
3. GPT-2: Scaling and Zero-Shot
GPT-1 proved that pre-training transfers well when followed by fine-tuning. GPT-2, introduced in Language Models are Unsupervised Multitask Learners, made a step further with the question: what if fine-tuning is not necessary at all?
This GPT-2 was done with a mindset that a sufficiently capable language model should be able to perform tasks without explicit supervision. If the training data is diverse enough, the model will have encountered text that looks like translation, summarization, question answering, as well as other tasks which are expressed naturally in human-written style. Therefore, a model which truly understands language should be able to recognize the implicit task structure from context alone and respond accordingly.
This point of view shifted the goal from transfer learning to zero-shot generalization, which then changed our understanding about language model fundamentals.
3.1 The Data Question
Instead of model architecture, the most consequential decision in GPT-2 was about data. The training data BooksCorpus, which was used for GPT-1, was large but narrow in style and domain. To train a model capable of generalizing across arbitrary tasks, the content needed to be diverse from news articles, forum discussions, technical documentation to programming code, recipes, and everything in between.
Researchers at OpenAI then constructed WebText, a dataset built by scraping outbound links from Reddit posts that had received at least three upvotes (which acted as a heuristic indicator of quality). Documents related to Wikipedia were removed to avoid overlapping with test set (as they usually appear in other datasets). The resulting dataset contained roughly 40GB of text across 8 million documents, covering a wide range of topics and writing styles.
The choice of WebText was itself a major improvement: the model's ability needed to reach a level of understanding the language existing on the internet, not only specific crafted scopes.
3.2 Architectural Changes
GPT-2 retains the same decoder-only, causally masked Transformer structure as GPT-1. The most significant change is the position of layer normalization. In the original Transformer and in GPT-1, layer normalization is applied after the attention and feed-forward sub-layers, i.e.
GPT-2 moves it to the beginning of each sub-layer (before the attention or FFN computation) as
This produces more stable gradients during training, which becomes increasingly important as the model grows deeper. The difference looked minor in terms of novelty, but such models with leading norm tend to train more reliably at larger scales. An additional layer normalization is also added after the final self-attention block (before the output projection).
Finally, the initialization scheme is adjusted so that weights in residual branches are scaled down by a factor of , in which is the number of residual layers. This prevents the residual stream from growing too large in deep models.
GPT-2 was released in four sizes to study how capability scales with model size:
| Model | Layers | Hidden size | Attention heads | Parameters |
|---|---|---|---|---|
| GPT-2 Small | 12 | 768 | 12 | 117M |
| GPT-2 Medium | 24 | 1024 | 16 | 345M |
| GPT-2 Large | 36 | 1280 | 20 | 762M |
| GPT-2 XL | 48 | 1600 | 25 | 1542M |
The context window was doubled from 512 to 1024 tokens, and the vocabulary expanded from ~40,500 to 50,257 tokens using Byte-Pair Encoding (BPE) at the byte level, which allows the model to handle any Unicode text without ever producing an unknown token.
3.3 Zero-Shot Task Prompting
Without fine-tuning, the only way to direct a GPT-2 model toward a specific task is through the prompt itself. Tasks are thus framed as natural text completions, for example:
- Translation: “Translate English to French: hello =”
- Summarization: “Article content:... Summarize it in a few sentences:”
- Reading comprehension: “Q: How many hours are there per day? A:”
The model finishes its task by continuing the sequence until the answer is complete. The task-related factor occurs only in inference stage without affecting the model weight.
This style of task specification through carefully crafted prompts later evolved into what became known as prompt engineering, which shapes how most people interact with language models today.
3.4 What GPT-2 Established
The experimental results in GPT-2's paper showed that its zero-shot performance was promising but inconsistent. In some evaluations (e.g. language modeling, reading comprehension, or text generation), it matched or approached the results of fine-tuned baselines, while in others it lagged far behind (e.g. translation, question answering, or summarization). It demonstrated that zero-shot learning was genuinely possible and the model was strong enough to demonstrate the viability of the concept, but still not large enough to realize it fully. In summary, GPT-2 led to 2 important factors for further NLP improvement.
- Scale matters: the larger GPT-2 models were qualitatively better at maintaining coherence over long input, not just marginally better on benchmark results
- Zero-shot learning was the right direction: no task-specific fine-tuning was required for general language understanding, it might instead just need a large enough model trained on text data of a wide scope.
4. GPT-3: Few-Shot Learning at Scale
The important conclusions of GPT-2 suggested the next step for unlocking zero-shot generalization: scale further. The GPT-3 model was then introduced in Language Models are Few-Shot Learners, which focused on what happens when the model is scaled by two orders of magnitude (dataset and model sizes). The answer was beyond just “better results”, there were new behaviors emerged (the ones which cannot, in my opinion 😶, be available in smaller models).
A key idea that emerged between GPT-2 and GPT-3 was the concept of scaling laws: as model size, training data, and compute increased, performance improved in a surprisingly predictable manner. This observation gave researchers confidence that simply scaling up the GPT architecture could continue to unlock new capabilities, a belief that heavily influenced the development of GPT-3.
4.1 The Scaling Hypothesis
In language models (as well as computer vision models), researchers have observed that there are three variables model size, dataset size, and compute that significantly contribute to performance, and scaling them may help the models discovering underlying hidden relationships inside training data (which may be not even obvious under human understanding). I had this impression when reading Quoc Le's papers (Unsupervised high-level features, EfficientNet) during my PhD 💡, but did not have opportunity to practice them, unfortunately.
GPT-3 was the most direct test for such scaling hypothesis, i.e. investing more resources into the same basic recipe may lead to more improvements, as it pushed the decoder-only architecture to 175 billion parameters (roughly 100 times larger than GPT-2 XL).
4.2 Architecture and Training
Structurally, GPT-3 was almost much larger scaled GPT-2 with one notable addition: alternating dense and locally banded sparse attention patterns were used in some layers like Sparse Transformer. In sparse attention layers, each token attends only to a local window of nearby tokens plus a strided set of more distant positions, rather than the full sequence. This reduces the quadratic cost of attention for longer sequences while preserving most of the representational capacity. The following figure (from another OpenAI's paper) shows different factorized attention schemes.
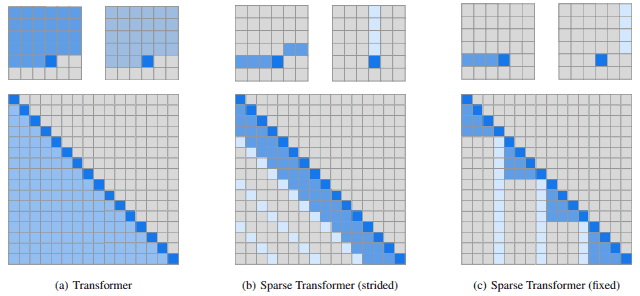
Two 2D factorized attention mechanisms compared to the full attention in Transformer
The top row illustrates an example of image where the input positions attended to by two attention heads when generating a specific output. The bottom row shows the corresponding connectivity matrix, where rows represent outputs and columns represent inputs. Because the connectivity matrix is sparse, these factorized schemes can substantially reduce computational cost.
The training data was a carefully weighted mixture of sources:
| Dataset | Quantity (tokens) | Weight in training mix* | Description |
|---|---|---|---|
| Common Crawl (filtered) | 410 billions | 60% | Text scraped from across the internet |
| WebText2 | 19 billions | 22% | Selected text from Reddit |
| Books1 & Books2 | 67 billions | 16% | Internet-based books corpora |
| Wikipedia | 3 billions | 3% | Structured Wikipedia articles |
* Weight in training mix refers to the fraction of examples that are drawn from the corresponding dataset during the training phase. As a result, some datasets are seen much more than others.
The raw form of the huge Common Crawl dataset is noisy and low quality. Some augmentations were employed, in which fuzzy deduplication was applied at document level to prevent memorizing and over-representing specific texts, and quality classifier (trained on high-quality datasets) was used to filter out low-quality text.
In order to study the dependence of performance on model size, 8 models with different numbers of parameters (from 125 millions to 175 billions, notice the change of unit as we may miss it - like I did when reading the paper at the first time 😓) were trained. The key architectural numbers across model sizes tested in the GPT-3 paper are summarized below.
| Model name | Total parameters | Layers | Hidden size | Attention heads | Head dimension |
|---|---|---|---|---|---|
| GPT-3 Small | 125M | 12 | 768 | 12 | 64 |
| GPT-3 Medium | 350M | 24 | 1024 | 16 | 64 |
| GPT-3 Large | 760M | 24 | 1536 | 16 | 96 |
| GPT-3 XL | 1.3B | 24 | 2048 | 24 | 128 |
| GPT-3 2.7B | 2.7B | 32 | 2560 | 32 | 80 |
| GPT-3 6.7B | 6.7B | 32 | 4096 | 32 | 128 |
| GPT-3 13B | 13B | 40 | 5140 | 40 | 128 |
| GPT-3 175B* | 175B | 96 | 12288 | 96 | 128 |
* flagship model |
The last model GPT-3 175B was roughly 1,400 times larger than the smallest variant GPT-3 Small. The context window doubled from GPT-2's 1024 to 2048 tokens, and the same byte-level BPE vocabulary of 50,257 tokens was reused.
4.3 In-Context Learning
The central idea of GPT-3 is in-context learning which is the ability to perform a task by conditioning on a few examples placed directly in the prompt (i.e. inference only, no update applied on the model's weights). This is distinct from both fine-tuning in GPT-1 (which modifies weights) and zero-shot prompting in GPT-2 (which provides no examples at all). The paper defines three settings for learning within the context:
- Few-shot: examples () are provided within the prompt
- One-shot: only one example is provided within the task description, i.e.
- Zero-shot: task is described in natural language without any example, i.e.
In all of the three above settings, the model's weights are fixed. Instead, the model seems to recognize the pattern demonstrated by the example(s) and extend it for generated tokens. While primitive forms of this behavior could already be observed in GPT-2, GPT-3 demonstrated it far more reliably and at a much larger scale.
4.4 Strengths and Weaknesses
GPT-3 performance was impressive on a wide range of benchmarks (e.g. translation, question answering, reading comprehension), even outperformed models designed for some specific tasks. The model was able to generate coherent long text of various formats, like code snippet or structured tables, but could also give wrong information which became widely known as hallucination.
Since GPT-3 was trained for next token prediction, it could continue smoothly an existing text in a natural way while having trouble following instructions strictly. For example, it may extend an article when being asked to summarize, or raise a question to answer another. In other words, it lacked a mechanism validating its output correctness. After all, the model focused mainly on continuing natural text generation.
4.5 What GPT-3 Established
GPT-3 confirmed the hypothesis that model ability can scale with its size, where it provided not only better results but also exhibited behaviors that are not available on smaller models. This finding reshaped research priorities across the entire field where most major labs switched toward even larger models.
In the opposite, GPT-3 demonstrated something less comfortable: the generated text may be impressive, but it may actually be misleading or even harmful. Addressing this gap became the challenge of the next generation.
5. GPT-3.5: From Raw Scale to Alignment
The reason for GPT-3 weakness was almost obvious. The training objective, i.e. predicting the next token, never considered the usefulness or safety of the model output. Fixing this required a fundamentally different kind of feedback. GPT-3.5 tackled it by encoding what humans actually wanted from a language model via reinforcement learning.
5.1 Brief Reinforcement Learning
Briefly, reinforcement learning (RL) is a framework for training a system to make good decisions by rewarding desirable outcomes and penalizing undesirable ones. Instead of learning from a fixed dataset of correct answers, an RL agent learns by interacting with an environment, receiving feedback under the form of a reward signal, and gradually adjusting its behavior to maximize that reward over time.
In the context of language models, the “agent” is the model, the “action” is choosing the next token, and the “environment” is the full context of the conversation so far. The challenge is defining the reward signal, i.e. what “good” actually means for a language model response. This is where human feedback is employed.
5.2 Reinforcement Learning from Human Feedback
The technique used to align GPT-3 into a more useful model (named InstructGPT) is called Reinforcement Learning from Human Feedback (RLHF). It was introduced in Training Language Models to Follow Instructions with Human Feedback with three stages.
Stage 1: Supervised Fine-tuning
Human contractors created high quality prompts and their corresponding ideal responses (in many possible forms such as conversation, instruction, question, or creative tasks). The pre-trained GPT-3 model was then fine-tuned on those data under the standard supervised strategy. As a result, the model output tended to follow the basic format of helpful responses such as answering the question asked, following the instruction given, and staying on topic.
Stage 2: Train a Reward Model
The fine-tuned model from Stage 1 was then used to generate multiple responses to the same prompt. Human raters then rank these responses from best to worst. From these rankings, a separate neural network, the reward model, was trained to predict such score which is likely one that human would assign to a response. Once trained, this reward model could replace the human effort in judging a response.
Stage 3: Fine-tune with RL
The language model is now fine-tuned based on feedback given from the reward model. An algorithm, named Proximal Policy Optimization (PPO), was applied to optimize the language model so that its responses tend to get high reward scores. Two complementary constraints prevent the model from reward hacking (producing responses that score well but are not actually useful):
PPO's proximal constraint, which clips each gradient update so the new policy stays close to the previous iteration
An explicit KL divergence penalty added to the reward which keeps the model from drifting too far from the original fine-tuned model (stage 1) across the entire training process
The full pipeline can be summarized as follows:
| Stage | Input | Output | Signal |
|---|---|---|---|
| Supervised fine-tuning | Prompt + human-written response | Fine-tuned LM | Cross-entropy loss |
| Reward model training | Prompt + multiple responses + human rankings | Reward model | Ranking loss |
| RL fine-tuning (PPO) | Prompt | Updated LM | Reward model score |
5.3 From InstructGPT to ChatGPT
InstructGPT was the direct product of applying RLHF to GPT-3. In human evaluations, the outputs from InstructGPT (1.3B parameters) were consistently preferred to those of GPT-3 (175B parameters) despite the significant difference in model size, and the model did better in following the instruction and declining harmful content in its generation. This was a clear signal that alignment quality and raw model size are separate axes. However, some limitations were still there, e.g. hallucination persisted, or the reward model could be bypassed. Another important point to notice: the major improvement in InstructGPT came from RLHF, which significantly depends on human, the model behavior could then be implicitly (and unintended) impacted because of the identity of people (their beliefs, background, history, ...) involved in the labeling step, e.g. those people were primarily English-speaking and the data consisted almost entirely of English instructions.
ChatGPT, released publicly in November 2022, was essentially a sibling model to InstructGPT, but introduced significant improvements specifically for natural conversation. It could hold a coherent multi-turn conversation, follow complex instructions, and adjust its tone and format to the context.
The success of those models demonstrated that making a model behave appropriately is a distinct engineering problem beyond just scaling its size. A valuable model requires a proper design choice as well as deliberate effort to get right. This realization reshaped directions of model development. Safety and alignment research, previously a relatively niche concern, became an important factor to consider in nearly every major lab's roadmap. The question was no longer just “how capable can this model be?” but also “how can we ensure it uses that capability in the desired way?”
6. GPT-4 & 5: LLMs Go Mainstream
As InstructGPT and ChatGPT had confirmed the strength of LLM in real world, the question then became whether they could be reliably capable as well as genuinely safe while broadly accessible, all at the same time. GPT-4 was OpenAI's first serious attempt to answer them all.
6.1 GPT-4: Multimodal and More Capable
In general, GPT-4 inherited the solutions and improvements of its previous generations. What changed substantially was the scope of allowed inputs, the scale at which it was trained, and the degree to which alignment was treated as a first-class concern rather than an afterthought.
Unlike the first three versions, GPT-4 was indicated in a technical report without details about architecture, model size, training data, preprocessing, or optimization. What the report confirmed is that “a core component of this project was developing infrastructure and optimization methods that behave predictably across a wide range of scales.” It allowed researchers at OpenAI accurately forecasting the capabilities and final performance (on some aspects) by observing the trajectories of smaller models trained at early steps. Since training such huge models is incredibly expensive and time-consuming, this ability of forecasting a large model's behavior by studying smaller ones was itself a major technical achievement.
Multimodal input
Beside text, GPT-4 also accepted images as input, making it possible to describe a photograph, interpret a diagram, or answer questions about a chart,... all within the same model. The output remained text-only, but the input modality was meaningfully expanded.
Context window
Two versions of GPT-4 were introduced with context windows of 8,192 and 32,768 tokens, which were significantly longer than previous models. Months later, GPT-4 Turbo, a more capable and cheaper version, was launched with a 128K context window (i.e. equivalent to more than 300 pages of text in a single prompt).
Benchmark performance
GPT-4 achieved comparable (or even better) performance compared to human test takers on a variety of standardized exams, including a simulated bar exam with the passed score around top 10% of test takers. The report evaluated GPT-4 across a wide range of standardized exams such as SAT, GRE, AP exams, and medical licensing tests. The report also carefully acknowledged that GPT-4 still had similar limitations to earlier GPT models: it was not fully reliable, could suffer from hallucinations, and had a limited context window.
Safety as a design priority
GPT-4 expanded safety work beyond post-training alignment by integrating extensive safety evaluation and testing throughout development. The technical report was accompanied by a detailed system card (starting from page 41) describing known risks and some strategies to apply (the term “system card” may cause confusion, I understood in that case it is a short document about safety evaluation and advice 😊). The failure rates of generating harmful output were also significantly dropped compared to its predecessor (GPT-3.5).
6.2 GPT-4o: Native Multimodal
The most significant update in GPT-4 family was GPT-4o (“omni”), which was capable of processing text, images, and audio within a single model. The major improvement was its native multimodal architecture: earlier multimodal GPT systems relied on separate modality-specific components to some extent, whereas GPT-4o was designed and trained as a more unified multimodal model. One practical consequence was significantly lower latency, matching human conversation speed and making real-time voice interaction more natural.
6.3 GPT-5: Unified System
GPT-5 is OpenAI's latest flagship GPT-family foundation model, announced in August 2025. There was no technical report published, instead only System Card. The most consequential architectural decision in GPT-5 is about unification in terms of product lines.
Previous GPT model families had diverged into standard GPT series for general language tasks and the o-series for step-by-step reasoning. Users had to manually choose which model to use depending on the complexity of their task. GPT-5 is a unified system with a real-time router that quickly decides which model to use (a model that answers most questions, and a deeper reasoning model for harder problems) based on multiple factors such as conversation type, tool needs, and the user's explicit intent. This routing mechanism was trained based on observations when users switch models and on which responses receive higher preference ratings, i.e. the system continuously improved its own judgment about quick versus deep responses.
Reasoning and hallucination
With web access enabled (i.e. allowing the model to access the internet) under OpenAI's test conditions, GPT-5's responses are approximately 44% less likely to contain major factual error than GPT-4o, and when thinking, the number becomes 78% (compared to OpenAI o3 model). The reduction of hallucination is the most substantial improvement on this dimension the series has seen.
Safe completions
Rather than refusing giving answers for sensitive questions, GPT-5 uses safe completion which gives high-level responses within safety constraints. This reflects a broader shift in how GPT models deal with safety problems: instead of blocking potential risky queries, finding helpful and safe responses should be preferred.
Conclusion
The GPT story is one of progressive reduction and progressive expansion. It began by stripping the Transformer down to its most minimal useful form: a decoder predicting the next token from everything that came before. From that single, simple objective, everything else followed.
GPT-1 showed that pre-training on unlabeled text yields representations that transfer across tasks, making task-specific architectures largely unnecessary. GPT-2 demonstrated that zero-shot generalization was not just a theoretical possibility but a practical outcome when training data was sufficiently diverse. GPT-3 confirmed the scaling hypothesis in the most direct way possible: investing more compute and data into the same basic recipe produces not just better results, but new behaviors like in-context learning that were not possible at smaller scales.
However, raw capability alone was insufficient. GPT-3.5 and ChatGPT showed that a model's usefulness depends not only on what it knows, but on how it behaves. RLHF introduced a mechanism for encoding human preferences directly into the training process, producing a model that humans preferred over its much larger predecessor. Capability and alignment had been decoupled from model size.
GPT-4 carried this philosophy further, treating safety as a training-time concern. GPT-5 then collapsed the product line, letting a learned routing system decide between fast responses and deeper reasoning chains without the user having to choose.
What the GPT series ultimately demonstrates is that the core idea of predicting the next token at scale was more powerful than it initially appeared. The fundamental architecture barely changed from GPT-1 through GPT-4. What changed was our understanding of what scale could achieve, and then our recognition that scale alone was not sufficient. Safety, alignment, and usability became equal priorities alongside capability.
Advanced Questions & Insights
Because next-token prediction can be implemented efficiently using only a decoder stack.
The encoder-decoder separation exists to handle the case where input and output are structurally different (e.g., two different languages). For text generation:
- Source and target are the same type of sequence
- The model only needs to predict what comes next, not transform one representation into another
Removing the encoder:
- Eliminates cross-attention entirely
- Allows any raw text to serve as a valid training example
- Makes the architecture scale more cleanly
Key insight: GPT does not require an encoder because next-token prediction can be formulated entirely with a causal decoder.
Fine-tuning modifies model's weights, while in-context learning does not.
Fine-tuning (GPT-1):
- Additional training on labeled data
- Weights change permanently
- Different models for different downstream tasks
In-context learning (GPT-3):
- Examples are placed directly in the prompt at inference time
- Weights remain the same (i.e. inference only)
- The same model handles arbitrary tasks
Key insight: In-context learning is pattern recognition at inference time without any gradient updates, not actual “learning” in terms of typical model training in machine learning.
Because capability is a major factor for generalization.
GPT-1 was capable enough to learn meaningful representations, but not capable enough to recognize task structure from context alone. Zero-shot behavior requires:
- Enough model capacity to hold diverse knowledge
- Enough training data diversity to have encountered many task formats naturally
- Enough scale (all axes) to combine both reliably
GPT-2 achieved this partially while GPT-3 more fully.
Reality check: The shift from fine-tuning to zero-shot is a consequence of scale other than a paradigm change in architecture.
Hallucination is when the model generates confident but false information.
It persists because:
- The training objective focuses on fluency other than factual accuracy
- The model has no internal mechanism to verify what it generates
- High-probability outputs can be entirely fabricated if the pattern fits the context
RLHF partially helps because human raters penalize obviously wrong answers. But it does not fully solve the problem because:
- Raters cannot verify every factual claim
- Fluent-sounding hallucinations may still receive high ratings
Key insight: Hallucination is widely believed to be related to the fact that language models are optimized for predicting plausible continuations rather than explicitly verifying truth.
RLHF reshapes the probability distribution over outputs. RLHF primarily changes behavior and preferences, although it can also affect measured performance on some tasks.
Before RLHF, the model assigns probability proportional to how likely text would appear in training data. After RLHF:
- Helpful, well-formatted responses become higher probability
- Harmful or off-topic completions become lower probability
- The model learns to respond to instruction format, not just continue arbitrary text
The model is not learning new facts. Its knowledge is unchanged. What changes is which outputs it prefers to generate given a prompt.
Key insight: A model that can generate something harmful is still able to do so after RLHF, it is just less likely to happen.
Because larger models can approximate more complex functions.
More parameters:
- Allow finer-grained pattern memorization
- Enable more refined generalizations
- Create more stable internal representations
More data:
- Reduces overfitting
- Exposes the model to more diverse patterns
- Improves generalization to unseen text
More compute:
- Explores more of the loss landscape
- Converges to better minima
Reality check: Scaling works empirically other than having a complete theoretical explanation for why it produces coherent capabilities.
GPT is decoder-only (causal); BERT is encoder-only (bidirectional).
GPT:
- Each token attends only to tokens before it
- Designed for generation: producing new tokens
- Trained to predict the next token
BERT:
- Each token attends to all other tokens in both directions
- Designed for understanding: embedding and classifying existing text
- Trained on masked token prediction and next-sentence prediction
The tradeoff:
- BERT produces richer contextual representations (sees full context in both directions)
- GPT can generate new text naturally (BERT cannot, since it requires seeing the future)
Key insight: The architectural choice is determined by the primary task, e.g. generation requires causal masking while understanding does not.
Probably not at the same rate, for both practical and fundamental reasons.
Practical limits:
- Training costs tend to rise faster than incremental performance gains, creating diminishing returns
- Energy consumption, hardware availability, and infrastructure become significant constraints
- The supply of high-quality training data may become a limiting factor
Fundamental limits:
- Scaling can reduce hallucinations but does not eliminate them
- Some capabilities may benefit from architectural innovations rather than scaling alone
The current trend:
- Scaling is being supplemented with better data curation, RLHF, reasoning chains, and tool use
- Models like GPT-5 combine routing and step-by-step reasoning rather than relying on a single massive model
Expectation: Scaling is likely to continue, but increasingly alongside architectural and training innovations rather than as a standalone strategy.